Kaggle是一個全球性的資料科學社群網站,上面有很多資料分析的比賽、資料分析的文章,以及可供下載的資料集。今天想跟大家分享一則資料分析的文章,作者(Meg Risdal)所要分析的資料集是有關鐵達尼號的乘客資訊,裡面使用到的data在Kaggle裡面可以下載。那我們就跟著他的腳步來走一遍資料分析。

以下是我們會用到的 package,所以我們就直接library進來。
library('ggplot2') # 視覺化
library('ggthemes') # 視覺化
library('scales') # 視覺化
library('dplyr') # 資料整理與轉換
library('mice') # imputation
library('randomForest') # 機器學習
接著讀入我們的資料集
train <- read.csv('F:/Users/yueh/Desktop/titanic08/train.csv', stringsAsFactors = F)
test <- read.csv('F:/Users/yueh/Desktop/titanic08/test.csv', stringsAsFactors = F)
先來看一下這兩個資料個別帶給我們什麼資訊。
str(train)
str(test)

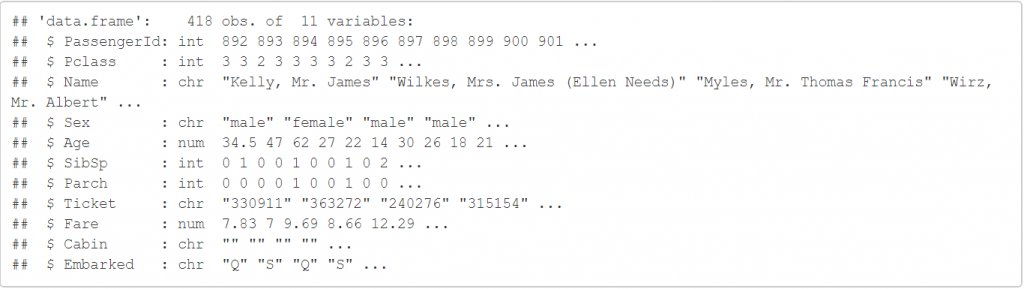
我們可以看到train有891筆資料,且具有12個變數。而test有418筆資料,且具有11個變數。他們不同的變數只差在train多了Survived這個變數。
而事實上,這筆資料原本是Kaggle上舉辦的機器學習競賽,train是訓練集,而test就是測試集。
在train裡面,我們有的變數是:
而我們的最終目的是去預測test裡面的乘客是否存活。
首先我們先把兩筆資料合併成一個資料框,如下:
full <- bind_rows(train, test) # bind training & test data
str(full)
雖然我們有了12種變數,但是這些變數(Feature)是否足夠好用呢?有些人可能聽過特徵工程( Feature Engineering ) ,其實就是把現有資料的變數轉換成 更有用 的變數。舉例來說,如果我們想要去預測一個人身高,但是我們只有手掌寬度的資料,那這筆資料有用嗎?
或許有用,也或許無用,但是如果我們能夠透過一些手法轉換成跟預測目標更相關的資料,使得資料變得 更有用 ,這個過程就是特徵工程的工作。在做資料分析的時候,最重要的環節其實是看著資料冥想(?),指的是去思考這筆資料能看到什麼?
在這邊 Meg Risdal 做了些很有趣的事情,對於初學得我來說會認為 PassengerId 和 Name 是無用的兩個欄位,不過國外的名子裡面多了一個特別的資訊:稱呼。所以 Meg 在這邊進行了稱呼的擷取,並且把稱呼新增成一個變數,和Sex繪製成一個table。
# Grab title from passenger names
full$Title <- gsub('(.*, )|(\\..*)', '', full$Name)
# Show title counts by sex
table(full$Sex, full$Title)

接著把title稍微調整一下,把Mlle跟Ms改成Miss,且把Mme改成Mrs,其他都統合到 Rare Title。
# Titles with very low cell counts to be combined to "rare" level
rare_title <- c('Dona', 'Lady', 'the Countess','Capt', 'Col', 'Don',
'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer')
# Also reassign mlle, ms, and mme accordingly
full$Title[full$Title == 'Mlle'] <- 'Miss'
full$Title[full$Title == 'Ms'] <- 'Miss'
full$Title[full$Title == 'Mme'] <- 'Mrs'
full$Title[full$Title %in% rare_title] <- 'Rare Title'
# Show title counts by sex again
table(full$Sex, full$Title)

然後我們也把姓氏給擷取下來,並且新增一個新的欄位(Surname):
full$Surname <- sapply(full$Name,
function(x) strsplit(x, split = '[,.]')[[1]][1])
既然我們有旁系血親個數,也有直系血親得個數,那們我們其實也可以算在同一艘船上的家族成員個數,並且也新增一個欄位。(Fsize)
並且把Surname和Fsize放在一起,看做是Family的變數。
# Create a family size variable including the passenger themselves
full$Fsize <- full$SibSp + full$Parch + 1
# Create a family variable
full$Family <- paste(full$Surname, full$Fsize, sep='_')
使用之前學的ggplot2來畫畫看圖表吧!
# Use ggplot2 to visualize the relationship between family size & survival
ggplot(full[1:891,], aes(x = Fsize, fill = factor(Survived))) +
geom_bar(stat='count', position='dodge') +
scale_x_continuous(breaks=c(1:11)) +
labs(x = 'Family Size') +
theme_few()
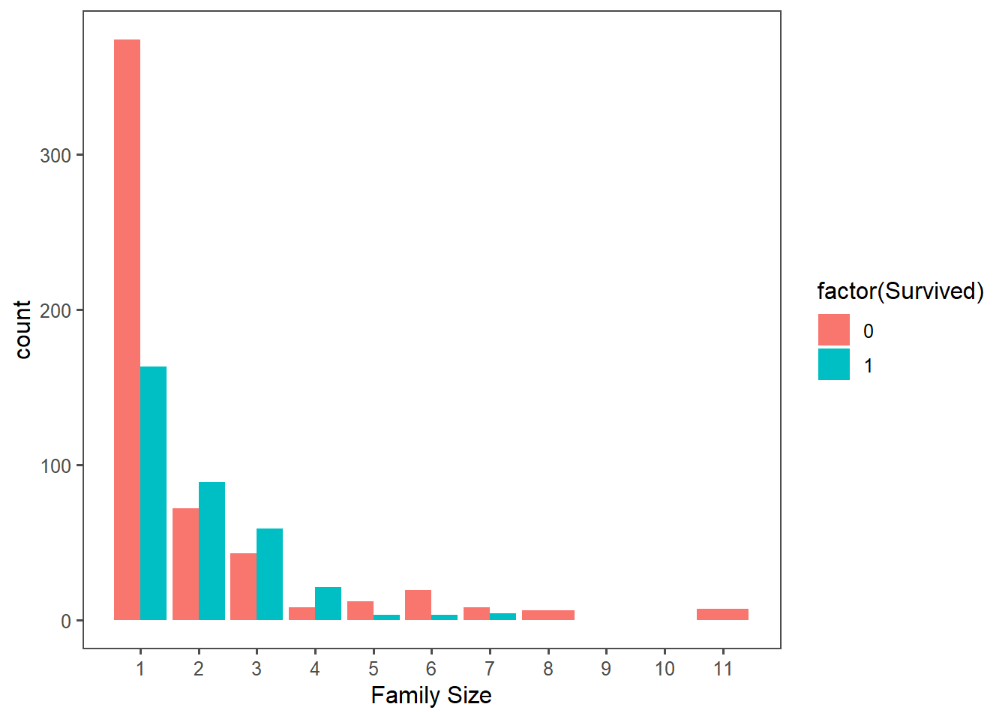
這個圖表是用Fsize和Survived去畫的,並且分成存活與未存活,從這個圖我們的確得到一些資訊,像是孤家寡人的生存率大概只有1/3,且8人以上的大家庭似乎沒人存活。那我們在做一些大膽的分類,把"孤家寡人"的人設成singleton,5人以上的稱做大家庭(large),剩餘的稱做小家庭(small)
# Discretize family size
full$FsizeD[full$Fsize == 1] <- 'singleton'
full$FsizeD[full$Fsize < 5 & full$Fsize > 1] <- 'small'
full$FsizeD[full$Fsize > 4] <- 'large'
# Show family size by survival using a mosaic plot
mosaicplot(table(full$FsizeD, full$Survived), main='Family Size by Survival', shade=TRUE)
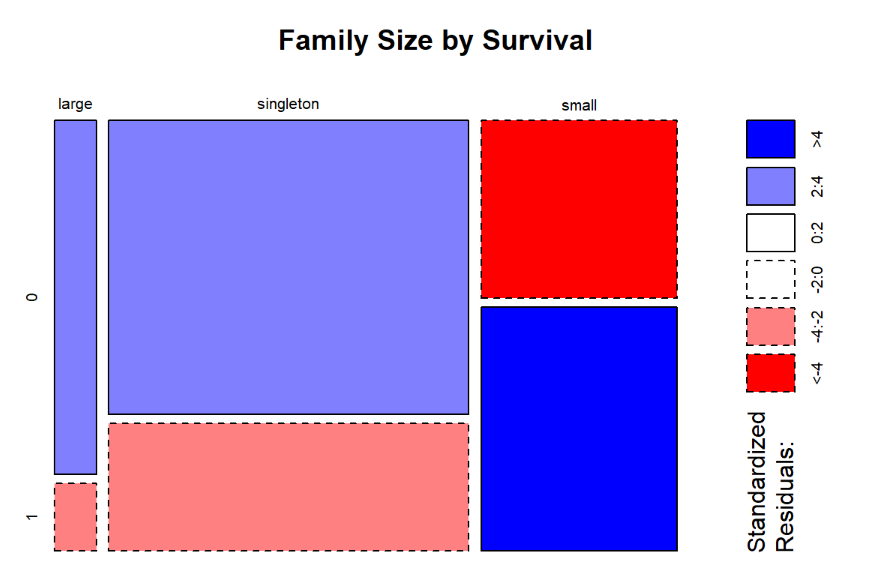
這個圖我們就可以很明顯看到,大家庭跟孤家寡人的存活率比小家庭低得多很多。
我們可以把客艙編號的字首也弄成一欄變,舉例來說C28,代表的是船艙C的第28號,現在我們只想要前面的字首。
full$Deck<-factor(sapply(full$Cabin, function(x) strsplit(x, NULL)[[1]][1]))
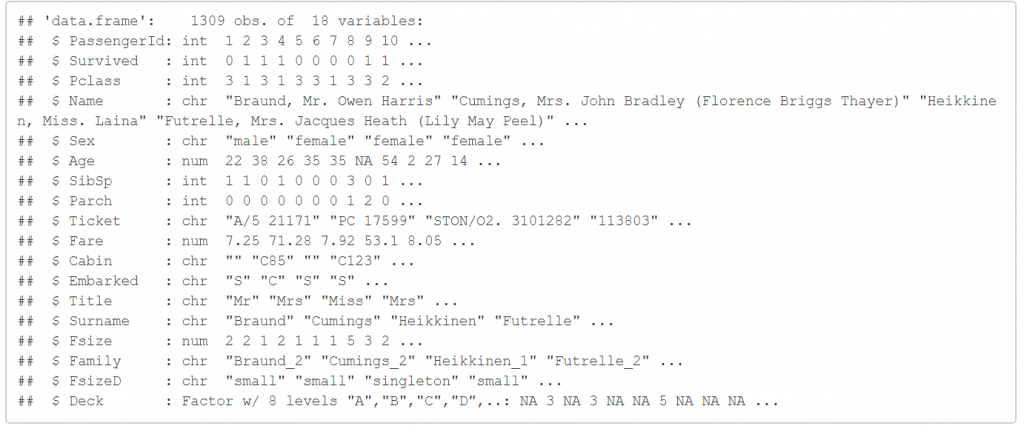
到這邊為止,我們的確新增了許多變數,目前的資料已經變成這樣。
str(full)
在下一篇文章,會針對缺失值(Missing value) 做一些處理,最後才會進行預測,這次的文章到這裡,謝謝大家。
原文網址:[https://www.kaggle.com/mrisdal/exploring-survival-on-the-titanic]
推薦文章:5 Steps of a Data Science Project Lifecycle
 df568923
df568923

 iThome鐵人賽
iThome鐵人賽